GiveUsAnA CS 175: Project in AI (in Minecraft)
Video
Project Summary
Our original goal of our project was to create an agent that can eliminate any enemy or enemies that appear in front of them as swiftly as possible while taking the least amount of damage. Our original idea was to put terrains and various obstacles in between the agent and the enemy and have our agent successfully maneuver toward the enemy. As our agent moved toward the enemy, the enemy would shoot weapon projectiles at the agent causing the agent to take damage. We also planned to create traps within the map that the agent could trigger and take damage. While maneuvering toward the enemy, our agent will also have to learn how to enchant their weapons, use potions, or use obstacles in order to avoid death. With all these factors coming into play, we wanted our agent to find the best path that would lead them to the enemy in which the agent also takes the least amount of damage. As time went out, we decided to tone down our project as it was too ambiguous and complex.
We wanted to get the basics down first so we could start small and build our way up. We decided to focus on getting our agent to move toward the enemy while taking the least amount of damage and then proceeding to kill the enemy. We planned to account for the extra external factors and commands like weapons and potion after we perfected our base case of just movement. However, we eventually decided to just focus on simple movement and pathfinding while ignoring the other external commands. Ignoring all the external factors beside an enemy and obstacles, we worked toward making an agent that can move around the obstacles toward the enemy and kill the enemy.
For the machine learning aspect of our project, we used a technique called the Asynchronous Advantage Actor-Critic (A3C) algorithm in order to implement our agent and AI learning. Originally used in an environment for the game DOOM, we have implemented it into our Malmo environment. Although A3C is the overall main technique, it uses aspects of Q-Learning to implement.

Approach
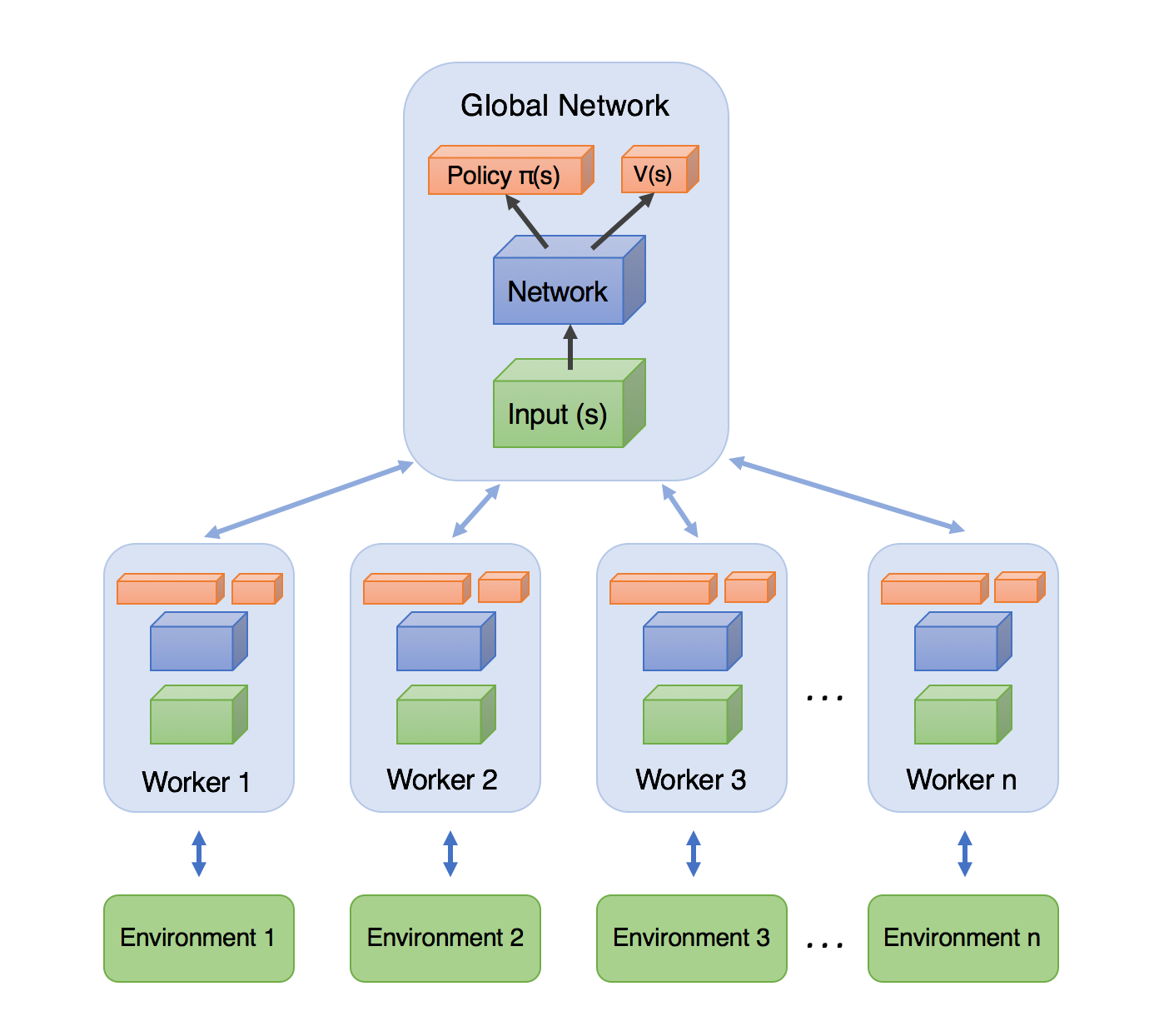
For our project, we will be using the Asynchronous Advantage Actor-Critic (A3C) algorithm in Tensorflow to create our agent. In A3C, there are multiple agent workers or “actors” who each have their own copy of the environment. These agents will each interact and train within their own environment at the same time, independent of each other. The agents will then relay informations gained back to the global network where the “critic” will adjust the global values based on information received. This method is beneficial because more work is getting done at the same time as well as the agent being independent from each other. The image below is a visual on how A3C is organized. There is a global network with its own policy function, value function, network, and input. This global network will send data down to many different workers with their own set of policy functions, value function, network, and input. The worker will then train within their own individual environment. The data from training in the environment will go back to the worker which will then relay it back to the global network.
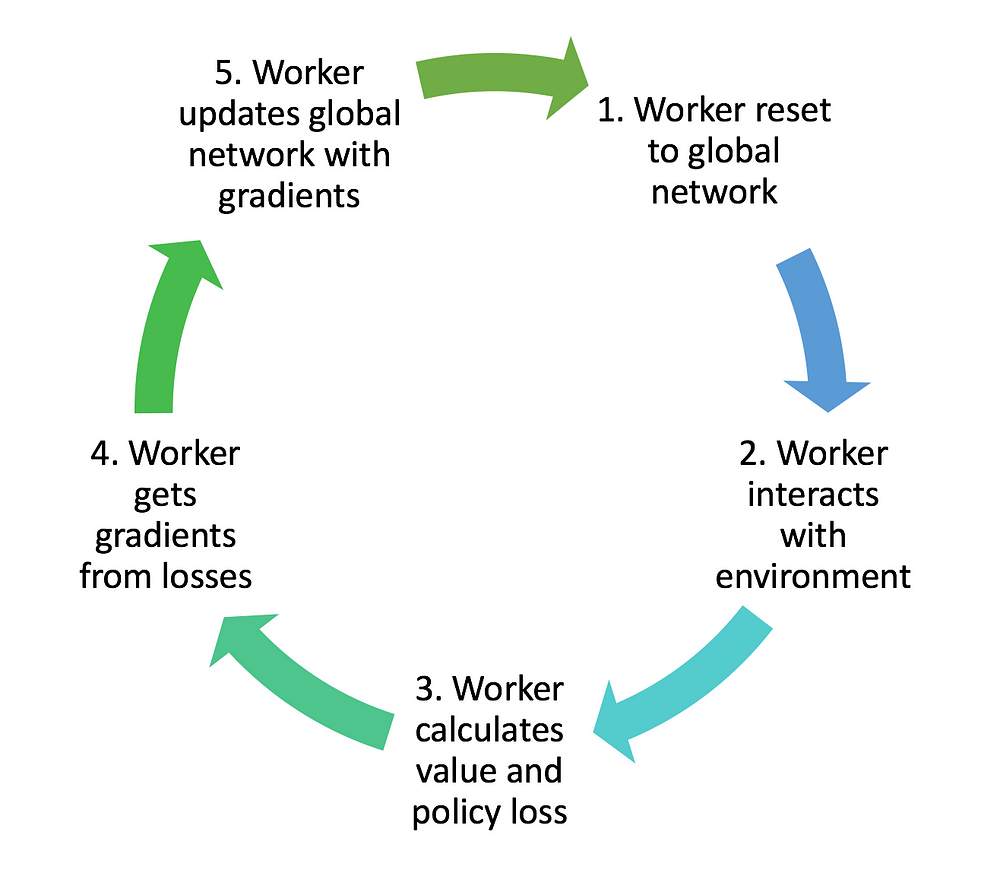
First, the A3C algorithm constructs a global network. Then worker agents are created with their own set of parameters, environment, and network. Each worker then set it’s own network parameter to match that of the global network. The workers will then interact within its own environment and collect its own data independent of the other workers. Once a worker has enough data, it will update the global network’s parameter. The worker will then repeat the whole process by resetting it’s own network parameter to match the global network’s new parameter.The image below shows the endless cycle of A3C in progress and how the whole network affects each other and loops around.
At the global network, there will also be a stochastic policy that represent the set of action probability outputs or the distribution of probablities over actions which should sum up to a total of 1.0. We determine how good a state is via the value function . The value function is an expected discounted return. The agent uses the value estimate set by the the critic to update the policy so that the agent can more intelligently obtain better results.
The action value function is essentially the Q-value from the method Q-Learning. It determines a value obtained from taking a certain action a on a certain state s. We obtain the weighted-average of for every possible action a that we can take on state s. The action value function is simply given the state s and action a which will result in only one next state at s’.
The advantage function is a function that when given an input of a state s and a action a, determines how good taking the action is compared to the adverage. If taking action a at state s leads to a result that is better than average, then the advantage function will be positive. If taking action a at state s leads to a result that is worse than average, then the advantage function will be negative.
In our advantage function of A3C, we can replace the action value function with the discounted rewarded value as an estimate value. This results in our advantage estimate equation.
With the data that a worker obtains, the discounted return and advantage is calculated. With those value, we can calculate the value loss and the policy loss. Using these losses, the worker can obtain the gradient taking into account it’s own network parameters. The gradient is then used by the worker to update the global network
The policy loss helps the actor determine which behavior/action taken was good and which was bad. This will help and make the agent do more beneficial and positive actions rather than negative actions. Both the losses are sent up to the global network along with other data in order to improve the whole system.
Although the A3C algorithm is outright impressive, we ran into several limitations as we completed our project. The A3C algorithm is a resource heavy technique. Each worker is a thread on the host machine and requires a separate instance of Malmo which destroys RAM and bogs down CPU. To alleviate resource drain it is possible to run instances of Malmo on a remote machine but now the local network must support the traffic. Scalability also became an issue as the current form will only support the available threads on a single machine.
Evaluation
Since the aim of our project is to have our agent reach the enemy while taking the least amount of damage, we will measure the performance of our agent by using the metric and statistics of the mission completeness time, how fast the agent kills/reaches the enemy, and how much health the agent loses during the fight. As the agent gets better, the agent should be able to reach the enemy faster while taking less damage.
The completion time of the mission will tell us how fast the agent has complete the mission by reaching and killing the enemy. As the agent gets better, the completion time of the mission should go down as the agent should learn the fastest path that will lead them to the enemy faster and kill them. The amount of health the agent loses during the mission is another metric that we will use to evaluate the success and result of our agent. As the agent gets better, the health lost should decrease as it should find better and safer paths to take in order to reach the enemy.
Since we were using the implementation of the A3C algorithm, we can also evaluate the success of the project by tracking the policy loss and value loss as our agent learns. With these two values, we can get our gradient that the algorithm will use to update the global network. We can also keep track of the reward values that the agent achieves after each run of the mission.




With the reward being tracked, we can see the agent learning and slowly achieving a higher reward value. Shown in the reward graph, at the start of our simulation as the agent was learning, the rewards would vary but as our agent got better, the reward that they achieved would consistently be high.

Resources Used
Resources that were used in our project includes a technique called Asynchronous Advantage Actor Critic (A3C) algorithm in Tensorflow. Links and information can be found below.
We would like to give a huge thanks to Professor Singh and our TA Stephen for guidance on our project throughout this quarter.