GiveUsAnA CS 175: Project in AI (in Minecraft)
Project Summary
In our initial project proposal, we wanted to make an agent that will eliminate enemies as swiftly as possible while taking the least amount of damage. Our original idea was to put obstacles in between the agent and the enemy and have our agent successfully maneuver toward the enemy as the enemy is shooting at the agent. While maneuvering toward the enemy, our agent will also have to learn how to enchant their weapons, use potions, or use obstacles in order avoid death. Although still our goal for this project, we first want to focus on getting our agent to move toward the enemy while taking the least damage without account for extra factors like weapons and potion first. For this status report, we are only working around getting an agent to move toward the enemy while taking the least amount of damage.
Approach
For our project, we will be using the Asynchronous Advantage Actor-Critic (A3C) algorithm in Tensorflow to create our agent. In A3C, there are multiple agent workers who each have their own copy of the environment. These agents will each interact and train within their own environment at the same time, independent of each other. The agents will then relay informations gained back to the global network where the “critic” will adjust the global values based on information received. This method is beneficial because more work is getting done at the same time as well as the agent being independent from each other.
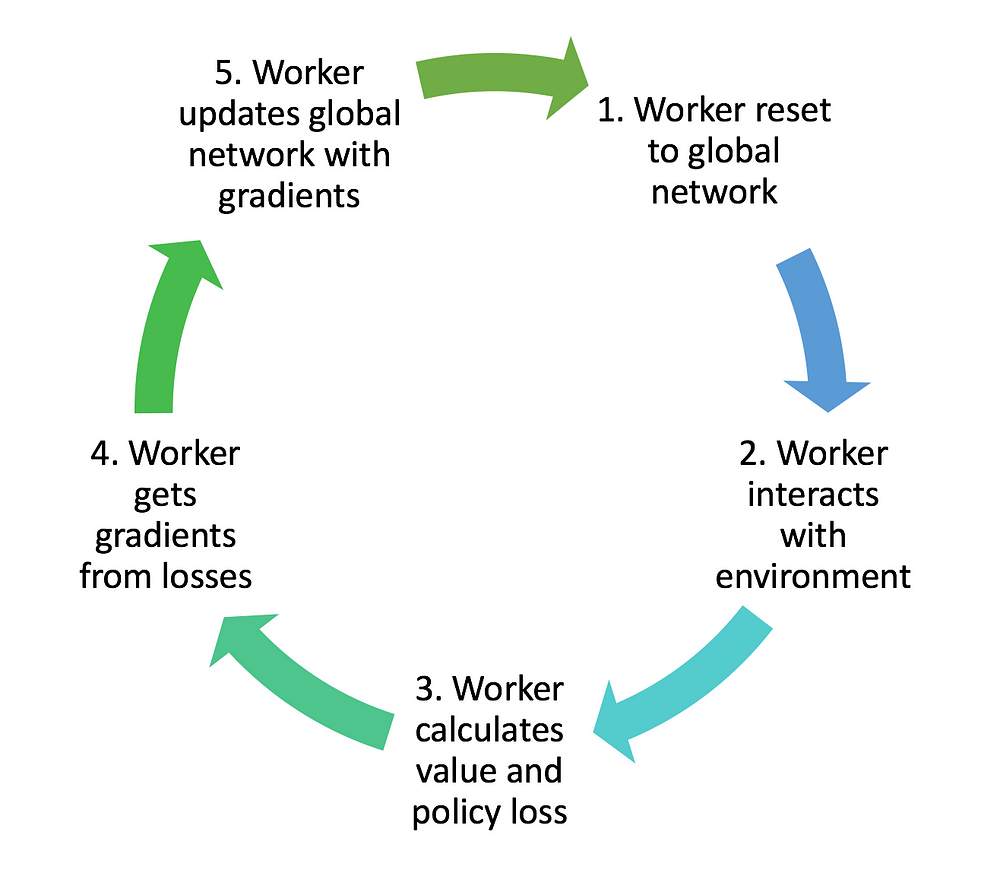
First, the A3C algorithm constructs a global network. Then worker agents are created with their own set of parameters, environment, and network. Each worker then set it’s own network parameter to match that of the global network. The workers will then interact within its own environment and collect its own data independent of the other workers. Once a worker has enough data, it will update the global network’s parameter. The worker will then repeat the whole process by resetting it’s own network parameter to match the global network’s new parameter.
At the global network, we determine how good a state is via the value function . There will also be a policy that represent the set of action probability outputs. The agent uses the value estimate set by the the critic to update the policy so that the agent can more intelligently obtain better results.
With the data that a worker obtains, the discounted return and advantage is calculated. With those value, we can calculate the value loss and the policy loss. Using these losses, the worker can obtain the gradient taking into account it’s own network parameters. The gradient is then used by the worker to update the global network
Evaluation
To measure the performance of our agent, we will use the metrics of agent health and the time to finish the mission (kill the enemy). The performance of our project will be measured by how much health the agent loses during it’s course to reach the enemy and how fast the agent kills/reaches the enemy. As the agent gets better, the agent should be able to reach the enemy faster while taking less damage.
In our project, we want the agent to get to the enemy location and kill them as quick as possible. We can see improvments based on how fast our agent actually gets to the enemy and kill them. We also want our agent to be able to take cover behind terrains or take paths that will remove them from the enemy’s range of fire. We will evaluate this portion by looking at how much health our agent has lost at the end of the mission. As our agent gets better, it should be learning the shortest path to reach the enemy in order to have a fast mission clear time. This shortest path should also be the path that results in the least amount of damage taken by the agent.
Remaining Goals and Challenges
Our ultimate goal for our project is to get the agent to swiftly move toward the enemy while taking the least amount of damage with the help and use of weapons, potions, and enchantment. At the time of this status report, we are only working on getting our agent to reach the enemy while not getting hit by the enemy. Our plans for the next few weeks is that if we can get our agent to get this baseline scenario down, we would hope to include the other aspects of weapons and potions.
We currently do not have a working version of the full A3C implementation. Instead of many asynchronous worker working at the same time, we currently just have one worker that is sole data provider to the global network. Our goal for the next 2-3 weeks would definitely be to complete the full implementation of the A3C algorithm with many workers instead of just one.
Based on our experiences so far, some of the anticipated challenges that we might face for the next 2-3 weeks will be completing the A3C implementation with many worker instead of just one worker. Our current prototype only includes movement commands for our agent and does not include other external commands like potions and enchantments. Our goal at the end is to allow agents to have access to more than just movement commands and we anticipate that adding potions and enchantments will require configuring our algorithm.
Resources Used
Resources that were used in our project includes a technique called Asynchronous Advantage Actor Critic (A3C) algorithm in Tensorflow. Originally used in an environment for the game DOOM, we are trying to implement it into our Malmo environment. Links and information about A3C can be found on our home page.